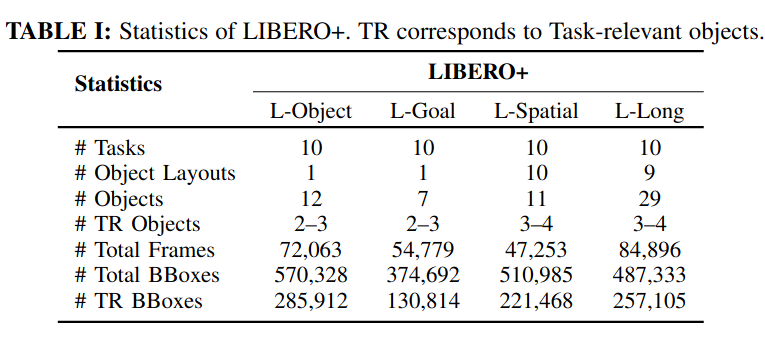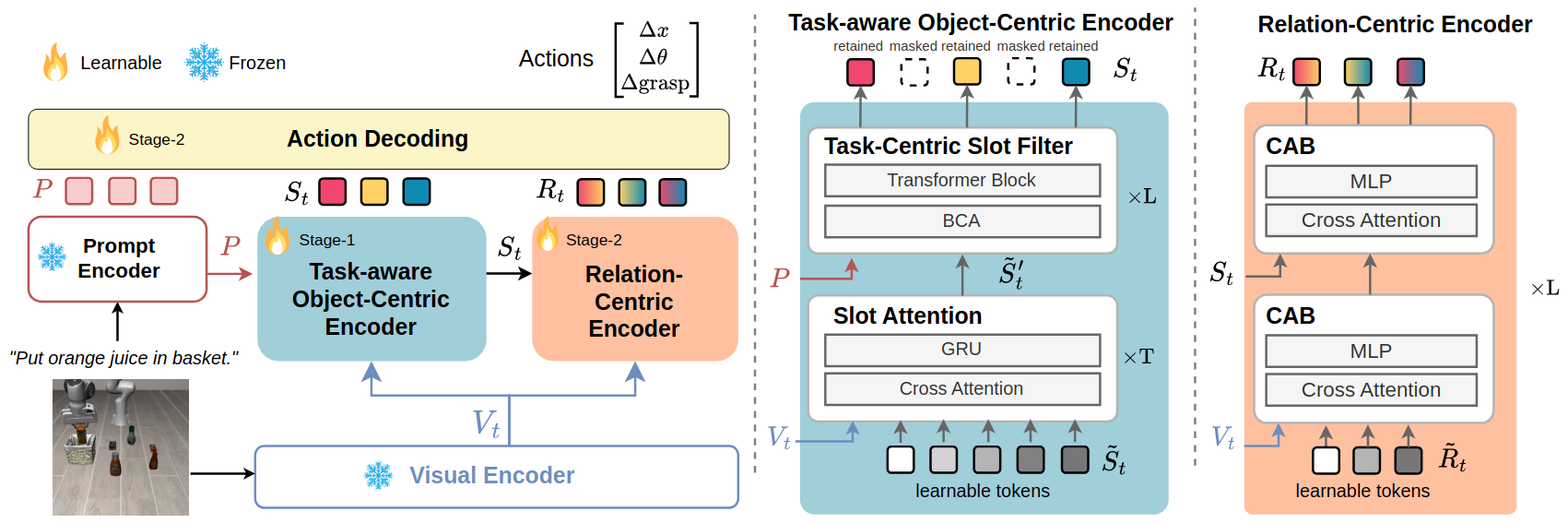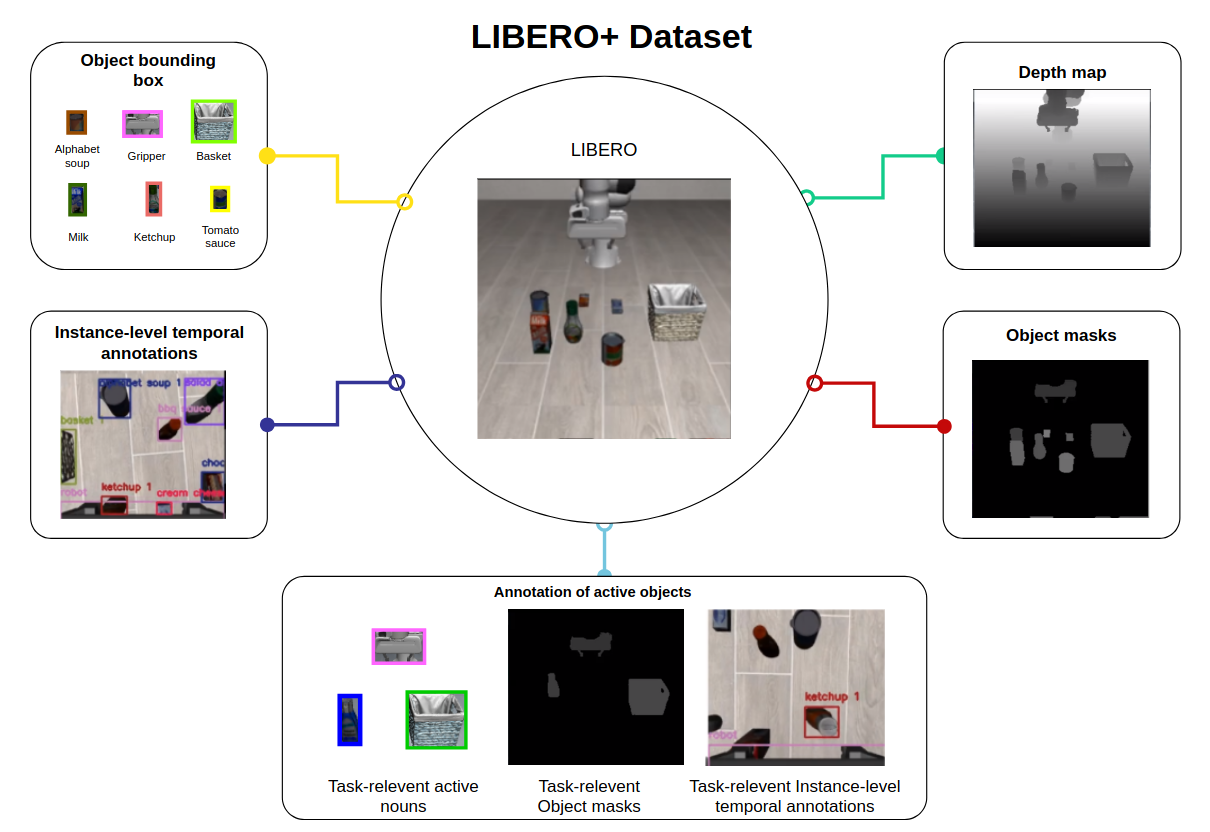
Inspired by how humans reason over discrete objects and their relationships, we explore whether compact object-centric and object-relation representations can form a foundation for multitask robotic manipulation. Most exist- ing robotic multitask models rely on dense embeddings that entangle both object and background cues, raising concerns about both efficiency and interpretability. In contrast, we study object–relation-centric representations as a pathway to more structured, efficient, and explainable visuomotor control. Our contributions are two-fold. First, we introduce LIBERO+, a fine-grained benchmark dataset designed to enable and evaluate object-relation reasoning in robotic manipulation. Unlike prior datasets, LIBERO+ provides object-centric annotations that enrich demonstrations with box- and mask-level labels as well as instance-level temporal tracking, supporting compact and interpretable visuomotor representations. Second, we propose SlotVLA, a slot-attention–based framework that captures both objects and their relations for action decoding. It uses a slot-based visual tokenizer to maintain consistent temporal object representations, a relation-centric decoder to produce task-relevant embeddings, and an LLM-driven module that translates these embeddings into executable actions. Experi- ments on LIBERO+ demonstrate that object-centric slot and object-relation slot representations drastically reduce the num- ber of required visual tokens, while providing competitive generalization. Together, LIBERO+ and SlotVLA provide a compact, interpretable, and effective foundation for advancing object–relation-centric robotic manipulation.